COMPUTER VISION
(http://www.theopavlidis.com/CvsH/Vision.htm)
Copyright ©2010 by T. Pavlidis
1. Why Computers Have Trouble Making Sense of Pictures
Anyone who has used a search engine, such as Google, has experienced how easy is to find documents that contain a given word (or words). But have you tried to find pictures with a certain subject? Unless the pictures are tagged (have text associated with them) you will be out of luck. Here is why computers find text much easier to deal with than pictures.
When text is stored on a computer, each character is translated into a number and the number is placed into computer memory. There are international standards for representing characters with numbers, the most commonly used is ASCII (it stands for American Standard Code for Information Interchange). For example, 65 stands for A, 66 for B, 97 for a, 98 for b, etc. Punctuation marks and spaces are assigned a code so that Brown fox becomes 66,114,111,119,110,32,102,111,120. (Of course the numbers are stored in binary form but that conversion is straightforward.) If you searching for documents with the word fox your query is converted into numbers (102,111,120) and searching for matches is reduced to matching strings of numbers, something that computers can do very well. The numbers are in the 0-255 range, so that each character is stored in a byte.
Pictures are also stored as strings of numbers, the colors at each pixel. The word pixel stands for picture element and here we come into the first fundamental difference between text and pictures. The characters in a text are natural elements and they describe the text whether stored in computer memory or chiseled in a stone tablet. When a person looks at a picture, he/she does not perceive any pixels. When a picture is taken with a digital camera is subdivided into tiny areas and information about their color is stored in the camera memory and, eventually, in computer memory. These tiny elements are the pixels. We know from physics that any color can be expressed as a combination of red, green, and blue and the standard is to express the strength of each color in the 0-255 range (so that it is stored in a byte). That gives a total of 2563 colors or more than 16 million, far more colors than a person can tell apart. (When the three colors are the same the picture appears gray, what we call "black-and-white photograph".) A typical camera may subdivide the scene into 1000 rows and 1000 columns, so that we have a million pixels and since each pixel has three byte, the picture requires three million bytes or three megabytes.
The trouble is that pixels have no meaning for humans. One must create from them other entities that capture properties of a picture that are meaningful to people and that is not an easy task. The great complexity of the visual system is detailed, amongst other places, in Chapter 4 of [1], where it is pointed out that the brain has models of the world (p. 68) and 30 distinct areas, each performing a different type of information processing, such as detecting color, texture, etc (p. 72). The authors note that "Perceptions emerge as a result of reverberations of signals between different levels of the sensory hierarchy, indeed across different senses" (p. 56). The complexity of the system may be also be inferred from the existence of visual illusions [2]. People have tried to describe pictures using statistics of the pixel values but they have not been successful. The difference between human perception of pictures and pixel statistics is called in the literature the semantic gap.
In contrast, text consists of words that are well-defined models of concepts so that communication amongst humans is possible. While words may be ambiguous, they are usually easily specified by content. Thus "dog" may mean either an animal or an unattractive person, but if we look at the words surrounding it, the meaning usually becomes clear. In turn, words have a formal representation either by single symbols (in Chinese for example) or by a sequence of symbols (in most languages). Whether one or several, the symbols have a well-defined representation in terms of bits, so going from digital storage to a human understandable representation is a matter of table look up. Figure 1 illustrates the paths from computer representation to human understanding for text and for pictures.
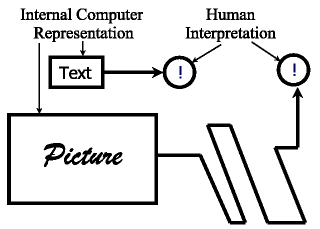 |
Figure 1: For
text the path from the internal computer representation to human
interpretation and understanding is short and simple, while for
pictures the path is quite long and tortuous. |
We may end with an observation from evolutionary biology. The human visual system has evolved from animal visual systems over a period of more than 100 million years (dinosaurs had a good visual system). In contrast, speech is barely over 100 thousand years old and written text no more than 10 thousand years old.
2. How Computers Can Make Sense of Pictures
2.1. Making Computers Read
Computers must do a lot of work to make any sense of pictures. Here is an example. Suppose we want to make the computer "read". Instead of typing a document we scan it and then ask the computer to go from the pixels of the picture to the character codes. (This is what Google is doing with old books.) The first task would be to decide which pixels are black and which are white. Black means that all colors are 0 and white means all colors are 255 but that is an ideal situation. In practice we have shadows and illumination variations from the scanner so the task is not simple, but let us assume we have marked all pixels as either black or white. We may identify parts of each row where all pixels are black and replace them by short line segments. Then we can group stacks of such segments and replace them by straight lines (vectors).
 |
 |
 |
| (a) | (b) | (c) |
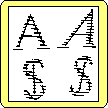
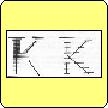
| Figure 2: The thin lines represent scan lines of the original bit image and the heavy lines the vectors produced by the computation. — Click on each image to see it in full scale. | ||
Figure 2a shows an example of the results of such a process. You can see that we have been able to represent each character by elements that are close to what a human may use to describe the shape of the character. But it has taken a lot of computation to do that and our results are not foolproof. The example of Figure 2b shows that such a representation can be effected significantly by slight changes in the shape of the original. Finally, the example of Figure 2c shows the results of another method that also produces straight line representations of numerals.
The straight lines computed in the examples of Figure 2 are close to the strokes that a person may use to describe the shape of the letter. However, this is only a first step. We have to create decision rules for determining the name of a letter from these strokes. Research in this area started in the early days of computers (in the 1940's) but high quality commercial systems did not become available until half a century later, in the mid-1990's. Today you can buy software (for under $100) that lets you scan a page and then convert it into a text file. However, because most documents are already available in electronic form the need for such conversions is limited. The technology is used by postal services to read typed or handwritten address but the need for such processing becomes increasing less frequent because paper mail is replaced by e-mail and FAX.
Before we leave the subject of computer reading we should say a few words about bar codes. Right after World War II several people identified the need to tag items with a computer readable code so that they could be tracked in shipping and in commercial transactions. Because reading digits was hard for computers engineers search for alternative marking systems and the eventual result was bar codes. Bar codes encode information in the width of black and white stripes thus the computer needs to do only the first step of a reading program: finding lines of pixels with the same color. Because only the horizontal dimension is used bar codes can be read by linear scanners that capture only one line across a label. Measuring the width of a stripe may be hard for humans but it is quite easy for computers. Bar codes offer a way for marking items with symbols that match the special abilities of machines.
2.2. Making Computers Find and Recognize Faces
Many modern cameras have the ability to detect faces in a picture. There are several ways to do that: one is to look for light color oval areas with four dark spots (eyes, nose, and mouth). Another is to look for oval shapes with flesh color, and, of course, a combination of the two. However, such methods have trouble dealing with the faces of bearded people or those wearing dark glasses. Figure 3 illustrates the challenge.
 |
Figure 3: The web site http://vasc.ri.cmu.edu/cgi-bin/demos/findface.cgi allows users to submit images and returns the results of a program for face detection, i.e. locating the face or faces in an image. Detected faces are marked with a green rectangle. A major miss is evident on the example shown. |
Recognizing faces is even harder. There has been a lot of publicity about computers looking at pictures of crowds and finding a particular individual (say, a suspected terrorist) there but the example of Figure 3 should make one skeptical about such claims. If it took nearly 50 years to develop machines that can read how long we should expect to take to make machines that recognize people? It appears that our brains have special areas dedicated to face recognition. This possibility can be inferred from the examples of Figure 4.
The task of finding the differences amongst each pair of pictures becomes much easier if we look at them right side up. From a mathematical viewpoint there should not be any difference. It is the circuitry of the human brain that is tuned to the way we usually see faces. You may also find that the difference in the ease of the task is bigger for the human face than the cat face. Why such a difference? Scrutinizing human faces is more valuable to people than scrutinizing cat faces.
 |
 |
| Figure 4: Can you find in what way the pictures in each of the above pairs differ? Click here to see the pictures right side up. (Or if you are reading this in a hard copy turn the page around. | |
Not surprisingly, the results of installed face recognition systems after 9/11 have been dismal. An ACLU press release of May 14, 2002 stated that "interim results of a test of face- recognition surveillance technology from Palm Beach International Airport confirm previous results showing that the technology is ineffective." The release went on to say that: "Even with recent, high quality photographs and subjects who were not trying to fool the system, the face-recognition technology was less accurate than a coin toss. Under real world conditions, Osama Bin Laden himself could easily evade a face recognition system. It hardly takes a genius of disguise to trick this system. All a terrorist would have to do, it seems, is put on eyeglasses or turn his head a little to the side." Similar conclusions appeared in a Boston Globe article of August 5, 2002. It quotes the director of security consulting firm saying that the "technology was not ready for prime time yet.'' He added that the " systems produced a high level of false positives, requiring an airport worker to visually examine each passenger and clear him for boarding." The article goes on to say: "One of the biggest deployments of the technology has occurred in England, in the London borough of Newham. Officials there claim that the installation of 300 facial-recognition cameras in public areas has led to a reduction in crime. However, they admit that the system has yet to result in a single arrest." A criticism of mechanical face recognition also appeared in the October 26, 2002 issue of the Economist. Ignoring the scientific evidence has resulted in a curious situation. The suppliers of the face recognition systems insist that the testers need to prove beyond reasonable doubt that their systems are faulty, instead of themselves having to prove that they are selling a valid product.
3. Some Fundamental Difficulties
One obstacle to making computers match human visual understanding is that it is very hard to model the human perception of similarity in mathematical terms (the only language computers understand). Consider, for example, the three shapes in Figure 5.
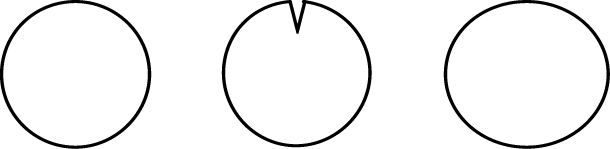 |
| Figure 5: Illustration used to explain the difference between humanly perceived and mathematical similarity. |
If you ask a person which one of the three shapes does not belong with the other two, most likely the answer will be the middle shape (circle with a notch). But computers must use mathematical formulas to compare the position of the pixels. It turns that the first two shapes are identical, except for the notch. If we overlay them on top of another (as the computer, effectively, does) they match everywhere, except at the notch, so their matching gets a high score. But the shape on the right is an ellipse, so it cannot be overlayed on the leftmost circle, so the matching will get a poor score. The computer answer will be that the shape to the right does not belong with the rest!
It is possible to write a program using different matching criteria (based on differential geometry) that will provide the same answer as people, but one can construct more complex examples where that program also fails to match human results.
| Sources Cited | |
|---|---|
| [1] | V. S. Ramachandran and S. Blakeslee Phantoms in the Brain, William Morrow and Company Inc., New York, 1998. |
| [2] | http://www.michaelbach.de/ot/ Web site of Professor Michael Bach of the University of Freiburg. |
First Posted: June 13, 2010 — Latest Update: June 13, 2010