PATTERN RECOGNITION
When people look at a scene and identify an object they do so by performing pattern recognition. Thus we recognize two dogs in the picture below even though the two creatures differ a lot from each other. People do not try to match any of the (sub)images to a prototype image. Instead they look at various characteristics (or features) and perform pattern recognition. In this case recognizing the pattern of a dog twice. Pattern recognition is used not only for pictures but also for sounds and in other situations such as medical or mechanical diagnosis.

We do not know how humans do pattern recognition. They rely on features but we do not know how they form the fetaures or how they combine them. We describe next how computers (or rather progams running on computers) use features.
FEATURES
THE WAY COMPUTERS DEAL WITH PICTURES
The raw data in a digitized image are simply a sequence of color values at each location that bear little relation to what a human sees. These values of little direct use even if very simple tasks.
Consider a security camera that takes pictures of a scene and we wish to detect if something has changed. Pixel by pixel comparison may give rise to false alarms because if the illumination changes only slightly it will produce different pictures. (Recall the example of the the three circles.) What we really want is to detect local changes (such as the notch in the three circle example) and that requires extra work.
{kind=link}
Computers must transform the pixel data into entities that relate to human perception. The simplest kind of such entities are numbers and they are usually called features. Let's continue with the security camera example and look at a picture that is the difference between two successive frames. Let us also assume for the moment that the camera is black and white so we do not have to worry about colors. We may compute the average difference Davg over all pixels and then calculate for each pixel the difference between its value and Davg and find the maximum difference (in terms of absolute value) MaxDif over the image. If this is small, then we may decide that the scene has changed uniformly and it must be the result of a change in illumination. Both Davg and MaxDif are features.
Usually features are computed on each image (or image part) and then they are used for the comparison. The process can be quite complex and involve several steps. One step may be vectorization where we replace the pixel description by a set of vectors. Examples are shown below.
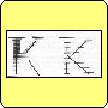
| Click on an image to see it in full scale. The thin lines represent scan lines of the original bit image and the heavy lines the vectors produced by the computation. The second example show that such a representation can be effected significantly by slight changes in the shape of the original. | 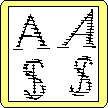
| 
|
The method used in the above examples requires that the scanned image that usually has 8 bits per pixel be converted into a binary image with one bit per pixel.
| It is possible to do the conversion directly from the 8 bit image as shown on the right. (Click on the shown image to see the full scale version.) While this requires more overall computation it is more reliable for noisy images where it is hard to decide whether a pixel should be black or white. | 
|
By going from pixels to vectors we also reduce the amount of data that need to be handled. A relatively small (256 by 256) pictures has 65,536 pixels but it may be reduced to, say, only 500 vectors. Each one them requires four values for its description so we end up with 2,000 numbers. This is important when we try to match an image to a set of other images in a set. Instead of comparing pixels we need to compare only features.
We may also derive other features from the lines, such as crossings and branchings. This is true for the important case of fingerprint identification. You can find more about the topic by visiting these web sites: Wikipedia entry for automatic fingerprint identification and Fingerprint Identification of Sharif University (good elementary discussion). There are many more web sites on the subject but they are advertise products or require login to view the full article. The following picture gives some idea about the kind of features used.
| One set of features used widely are the so called minutia that consists of ends of ridges or branchings of ridges. (Click on the shown image to see the full scale version. The picture is from a paper by Roddy and Stosz, published in 1997.) | 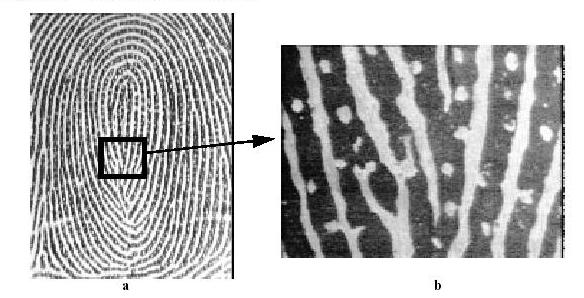
|
Of course, vectors are good features only for pictures that were supposed to be line like to start with as it is the case with letters and numbers or with fingerprints. Other kinds of pictures require far more complex (and time consuming) operations before they can be reduced to meaningful pictures.
The above discussion is meant only to give you a taste of the difficulty of the problem. One must write several thousand lines of code to achieve a task that is trivial for people.
Last Update 4/10/07