MACHINE LEARNING
Copyright ©2010 by T. Pavlidis
Can machines learn? The answer depends on what do we mean by learning. Machines cannot learn the way people do but they can learn to categorize objects after a machine is presented samples from each of several categories. For example, reading machines learn to read after been given samples of each of the letters of the alphabet. Usually they need thousands of samples of each letter in contrast to humans who can learn a new alphabet given only a few examples of each letter. We will return to this issue when we discuss reading machines.
In order to understand machine learning we need to explain how computers make decisions about categorizing objects. To start with, a physical object must be converted into a numerical representation, computers can deal only with numbers. (Actually only with zeros or ones but the conversion of other numbers to binary is automatic.) Sometimes the object is defined by numbers to start with and we will start our discussion with such case.
Suppose we want to have a medical diagnostic computer program that will categorize people as being at risk for a heart attack or not. We may decide to do that on the basis of total cholesterol in the blood and the body mass index (BMI) that gives an indication of whether someone is overweight. It is computed by diving the weight of a person in kilograms by the square of his height in meters and the ideal BMI is 25. Please do not assume that what we describe next has any medical significance. We will use the example only to illustrate machine learning and we are deliberating omitting calibrating the axes. A real diagnostic system must consider more factors. Furthermore the BMI is not a reliable measure of being overweight (see a critique of BMI). Also total cholesterol is not the best indicator, most physicians focus on the low density cholesterol.
In order to design the diagnostic program we collect data from individuals who had a heart attack and a group who are healthy. Because we deal with only two numbers we can plot them in a graph where the horizontal axis corresponds to the BMI and the vertical axis to the cholesterol. The points on the plane are marked with dark circles for people who had heart attacks and with open circles for the healthy subjects.
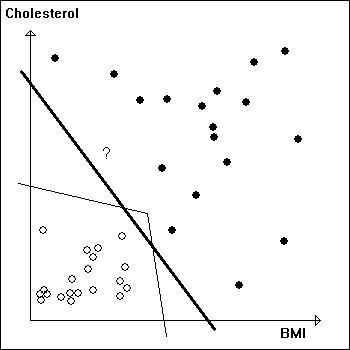 |
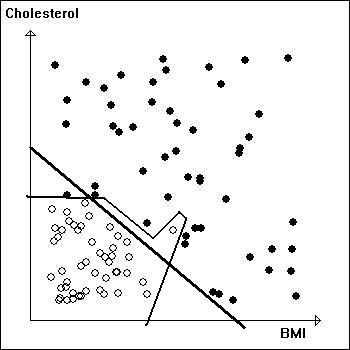
Example 1 We can draw a line or another curve to separate the two groups of points and the equivalent computation can be carried out by a computer program. The diagram on the left shows two possibilities. A line (heavy) or part of a polygon (thin lines). When the machine determines a rule for separating the two groups of points we say that the machine has learned to distinguish between the categories. The computer can now predict whether a patient is in risk for a heart attack or not. The patient's cholesterol level and BMI determine a point on that plane, for example the one marked with a "?". In this case the computer will decide that the patient is at risk. |
 |
|
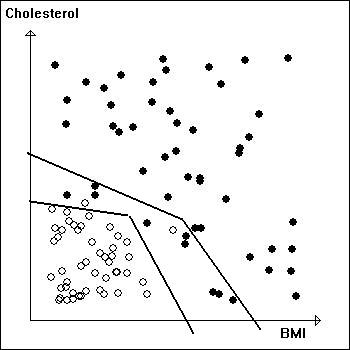
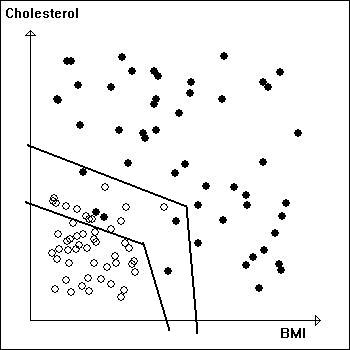
Example 2: Things are not always as neat as in Example 1. In the diagram on the left the data are mixed and a straight line no longer separates the two categories. However a polygonal line does the job, so the question is whether the separation of the two categories in this way is reliable. A safer approach is shown on the right. We have used two polygonal lines and we refrain from making a decision for the points between these polygonal lines. Thus the plane is separated into three zones indicating "healthy", "uncertain". and "at risk". | |
 |
|
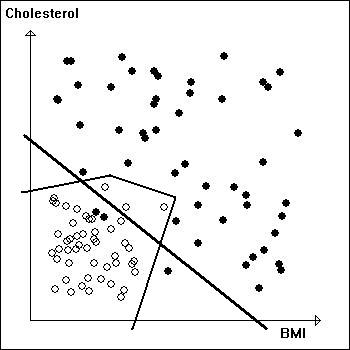
Example 3: Things are even tougher here than in Example 2. In the diagram on the left not even a polygonal line can separate the two categories. We have no choice but to use three zones as shown on the right. | |
We have used a graphical way to describe this simple diagnostic system only for illustration. In a real system the computer calculates a mathematical expression based on the measurements and it determines boundaries so that the expression gives two different values depending on which side of the line (or the polygonal line) a data point is. The parameters of the formula and the separating lines are adjusted until the values of the formula are consistent with the labeling (healthy or heart attack victim).
| Example 4: A Mathematical Digression | ||||
|---|---|---|---|---|
| ||||
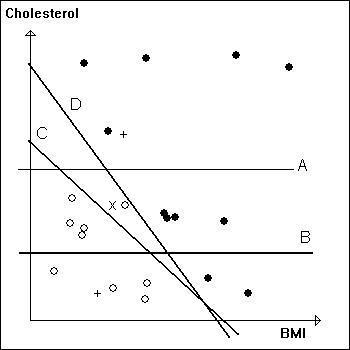
The important point to keep in mind is that all computer "learning" is equivalent to searching for parameters so that a mathematical expression returns values that are consistent with the classification of the "learning" samples. When a new sample is seen we classify it according to the value returned by the expression. The objects of interest may be described by more than 2 numbers (they usually run to the 100's) and the expressions can be far more complex than what we showed in Example 4 but the deep issues are the same. In particular:
A. Should we use simple expressions and allow for data that we cannot classify (as in the right side diagrams of Examples 2 and 3) or should we use more complex expressions and try to classify everything (as in the left side diagram of Example 2).
B. How many samples are enough for the learning stage? Example 1 had 40 samples, Examples 2 and 3 each had about 100, and Example 4 had only 20 samples. Clearly the size of the sample has an effect on how hard is the classification problem.
C. Are the object descriptions capturing all that is relevant for the classification task? In our "medical" example we have omitted such variables as genetic predisposition, blood pressure, etc. A practically useful diagnostic system should include all these.
It is appropriate to conclude this section with the observation that some impressive computer programs do not use learning at all. The following is a quote from the article "The making of a chess machine" by Eric J. Lerner. The articles deals with Deep Blue, the chess machine that beat the human world champion. For the full article see: http://domino.watson.ibm.com/comm/wwwr_thinkresearch.nsf/pages/deepblue296.html
Getting a chess machine to learn from its own mistakes is an appealing idea. It has been tried in the past, but with limited success. ... In contrast, Deep Blue has no learning ability once its values are chosen by its programmers; it carries out exactly the evaluations hardwired into it. So, in any dictionary definition, as well as in the eyes of its creators, Deep Blue has no intelligence at all. That point seemingly got lost in the media discussion of Deep Blue's IQ.
First Posted: May 30, 2010 — Latest Update: May 31, 2010